Share searchable versions of your CSVs online with Datasette & Glitch
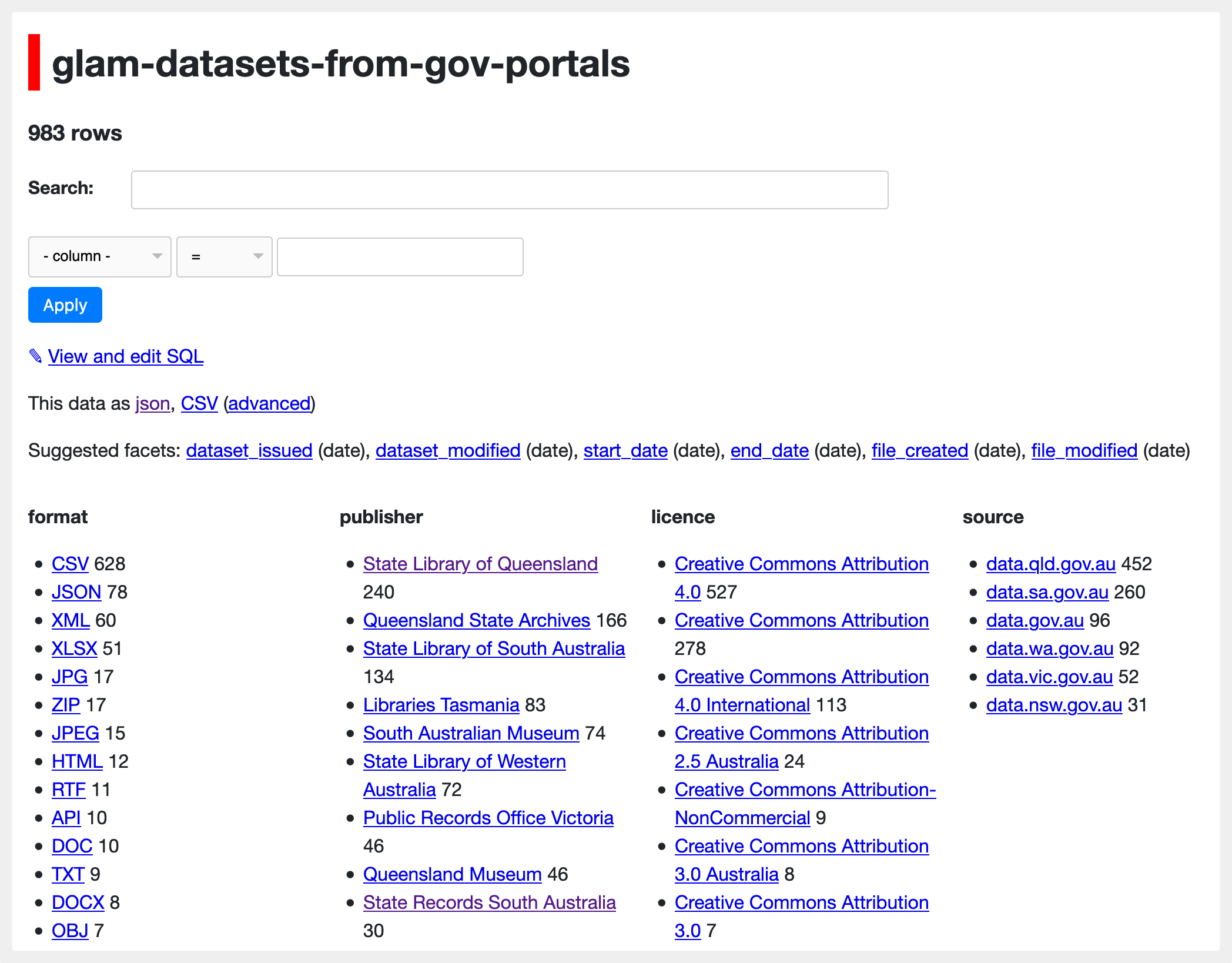
Recently I updated my harvest of GLAM datasets from national and state government data portals. The harvesting process generates a CSV file that includes basic metadata describing each file – there’s currently 983 of them!
After previous harvests I’ve uploaded the CSV with all the metadata to GitHub, a put a copy in Google Sheets to make it easier to search. This time I wanted to see what I could do with Datasette, Simon Willison’s fabulous tool for exploring and publishing data. In particular, I wanted to try out the remixable version of Datasette on Glitch. Here’s the final result.
Why not try it yourself? As you’ll see below, the combination of Datasette and Glitch makes it very easy for you to share a searchable version of your data, complete with facets, SQL queries, and even an API!
Quick start
It could hardly be simpler. Here are the basic steps:
- Go to Simon’s Glitch starter kit.
- If you haven’t already, log in to Glitch, or create a new account. This will make sure your new project is saved.
- Click on the Remix your own button to open your own copy of the project.
- Drag and drop your CSV file onto the list of files.
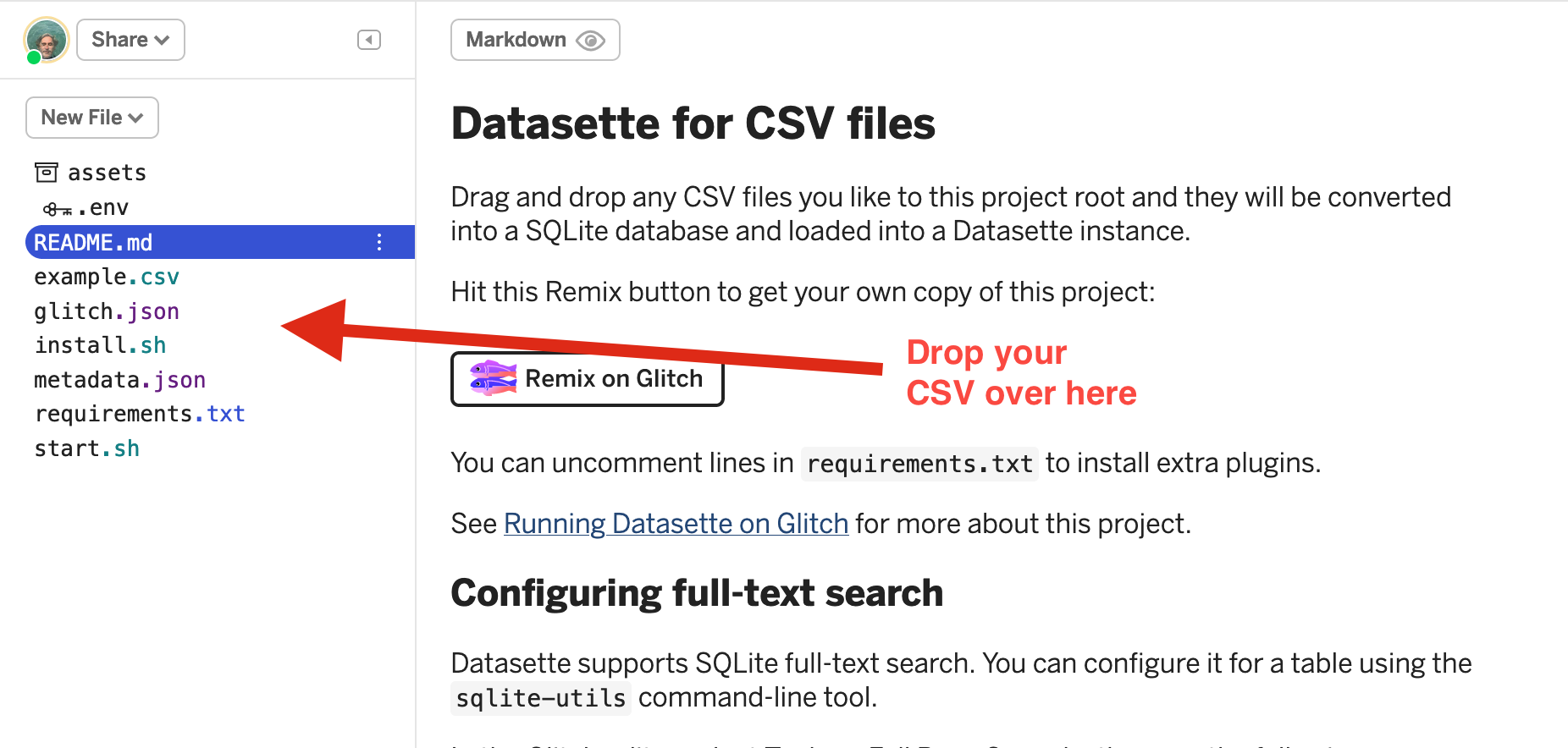
- From the top menu select Show > In a new window to open a new page and start exploring your CSV!
Customisation
Change the title and description
To change the default title and description, you need to edit the metadata.json file:
- Click on
metadata.jsonin the file list to open it for editing. - You’ll see two labels,
titleanddescption_html.1 2 3 4
{ "title": "datasette-csvs", "description_html": "<p>An example of how to run <a href=\"https://datasette.readthedocs.io/\">Datasette</a> on Glitch.</p><p>Hit the Remix button to get your own copy of this project, then drag-and-drop your CSV files into the Glitch editor to start interacting with your own data.<p><a href=\"https://glitch.com/edit/#!/remix/datasette-csvs\"><img src=\"https://cdn.glitch.com/2703baf2-b643-4da7-ab91-7ee2a2d00b5b%2Fremix-button.svg\" alt=\"Remix on Glitch\" /></a></p>" }
- Just change the values to whatever you want, but remember to enclose them in double quotes. Here’s what my
metadata.jsonended up like:1 2 3 4
{ "title": "Australian GLAM datasets", "description_html": "<p>Datasets created or published by Australian GLAM (galleries, libraries, archives, and museums) organisations, harvested from national and state government data portals.</p><p>See the <a href='https://glam-workbench.github.io/glam-data-portals/'>GLAM Workbench</a> for more details.</p>", }
- As the name suggests,
description_htmlcan include HTML tags. You can see I included a link to the GLAM Workbench. These values are used on the home page that Datasette creates for your data. Here’s what mine looks like.

See the Datasette documentation for a full list of values you can customise in metadata.json.
Full text search
There are a few other things you can do to customise the interface. If you’d like to make some of the columns searchable as full text, just do this:
- Click on
install.shin the file list to open it for editing. - At the bottom of the file, add the following line:
1
sqlite-utils enable-fts data.db [YOUR DATA FILE] [COLUMNS YOU WANT TO SEARCH] --fts4
In my case, the name of my CSV file was
glam-datasets-from-glam-portalsand the columns I wanted to make searchable weredataset_title,dataset_description,file_title, andfile_description. So I added the line:1
sqlite-utils enable-fts data.db glam-datasets-from-gov-portals dataset_title dataset_description file_title file_description --fts4
- Done! Reload the Datasette exploration page and you’ll see there’s now a search box.
Facets
By default, Datasette will try and automatically identify facets that slice up your data in useful ways. This didn’t quite suit my data, so edited the metadata.json file to specify the columns I wanted to be faceted.
- Click on
metadata.jsonin the file list to open it for editing. - The contents will look like this:
1 2 3 4
{ "title": "datasette-csvs", "description_html": "<p>An example of how to run <a href=\"https://datasette.readthedocs.io/\">Datasette</a> on Glitch.</p><p>Hit the Remix button to get your own copy of this project, then drag-and-drop your CSV files into the Glitch editor to start interacting with your own data.<p><a href=\"https://glitch.com/edit/#!/remix/datasette-csvs\"><img src=\"https://cdn.glitch.com/2703baf2-b643-4da7-ab91-7ee2a2d00b5b%2Fremix-button.svg\" alt=\"Remix on Glitch\" /></a></p>" }
- You need to add a new entry for
databaseswith a few levels of nested data. I wanted facets on thesource,publisher,format, andlicencecolumns, so mymetadata.jsonfile ended up looking like this:1 2 3 4 5 6 7 8 9 10 11 12 13
{ "title": "Australian GLAM datasets", "description_html": "<p>Datasets created or published by Australian GLAM (galleries, libraries, archives, and museums) organisations, harvested from national and state government data portals.</p><p>See the <a href='https://glam-workbench.github.io/glam-data-portals/'>GLAM Workbench</a> for more details.</p>", "databases": { "data": { "tables": { "glam-datasets-from-gov-portals": { "facets": ["source", "publisher", "format", "licence"] } } } } }
- For the sake of performance I decided to index the faceted columns. As above you need to open the
install.shfile for editing. - At the bottom on the
install.shfile add the following line:1
sqlite-utils create-index data.db [YOUR DATA FILE] [COLUMNS YOU WANT TO INDEX]
So in my case, I added the line:
1
sqlite-utils create-index data.db glam-datasets-from-gov-portals source publisher format licence
- Done!
